snowflake
The foundations of Canva’s continuous data platform with Snowpipe Streaming
Leveraging Snowpipe Streaming to build a continuous data platform.

In a previous blog post, we discussed the important role product analytics plays in helping teams measure the impact of their product features and, subsequently, make data-driven decisions. Over the past 5 years, Canva’s monthly active users have more than tripled from 60 million active users to over 200 million. In that time, Canva has also grown to over 4500 employees. As a result, the multiplicative effect of more questions from more internal customers with our user base generating bigger answers has driven us to find ways of scaling our product analytics platform for the future.
As a platform, we have 3 core questions we ask when making decisions about our roadmap. How can we answer:
- Bigger questions cost effectively?
- Questions in a shorter amount of time?
- Questions with greater correctness?
These questions led us to introduce changes such as better schema management across our analytics for more correctness, changing how we stream data, and many methods of reducing costs through improved performance. For more information about these changes, see Product analytics event collection.
Over time, these incremental improvements left 1 major change to reduce costs: pushing data to our Snowflake data platform. Since the platform’s inception, we’ve used AWS Data Firehose(opens in a new tab or window), which provides a convenient serverless option for landing data in S3.
Using S3 as a destination provides a great way to aggregate data across many consumers and to create right-sized files for the end user. This is an important feature of any tooling that pushes data to be consumed by batch processes, and in particular, data platforms because they tend to suffer from the small files problem(opens in a new tab or window).
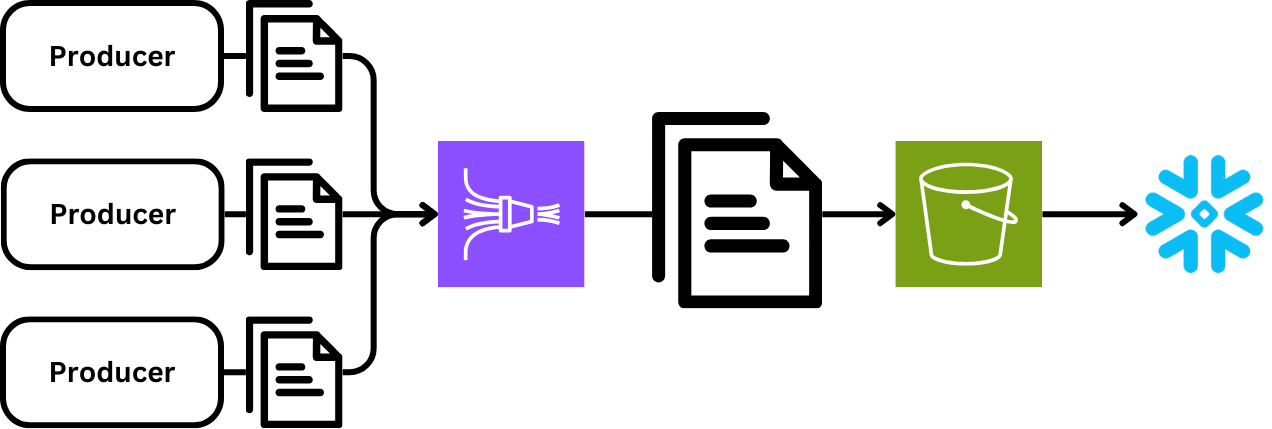
Firehose did a great job of scaling with us and continues to power many use cases at Canva with awesome features such as Dynamic Partitioning(opens in a new tab or window) and its varied set of destinations(opens in a new tab or window). The Firehose team is a great partner and constantly builds new features that make Firehose even easier to use.
Unfortunately, as our data volume grew, so did the cost, representing nearly 50% of the cost of our platform. One reason for this cost increase is that Firehose has a key limitation where records for billing purposes have a 5 KB minimum size(opens in a new tab or window), and when using S3 as a destination, billing increases in 5 KB increments. In a previous blog post, we cited 25 billion records a day as our throughput. Using the AWS Pricing Calculator, the math is easy to see.
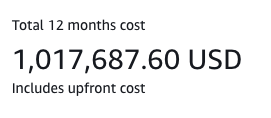
Also, this cost doesn’t account for any records larger than 5 KB or using Kinesis Data Streams as a source, which increases costs by 30%. The question is, how do we drive this number down?
Reduce the cost of Firehose
The first obvious thing to do was investigate how to drive down Firehose usage without changing the system. We switched from using Kinesis Data Streams as a source to Firehose Direct PUT, which reduced the cost of landing data by 30%.
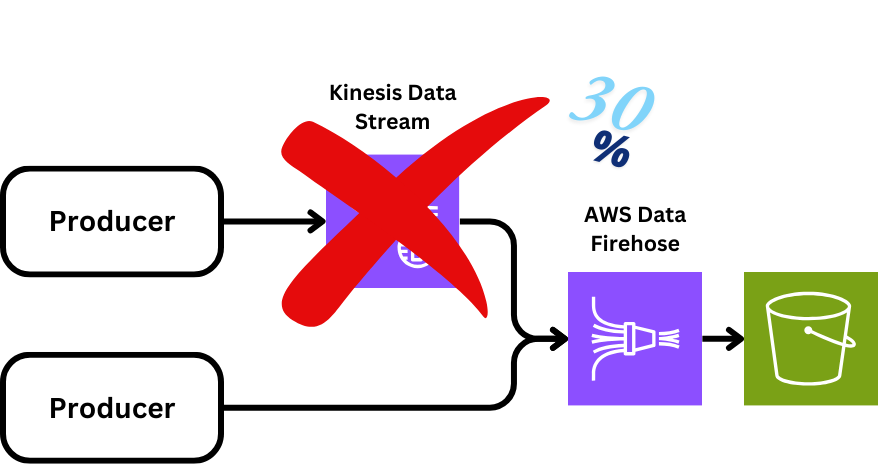
One of the disadvantages of Firehose is that it doesn’t auto-scale unless it’s tied to a data source that itself scales. In this case, we use Kinesis Data Streams in front of Firehose to allow us to scale freely. To scale up without it, we needed to submit a support ticket, which could take up to 24 hours to be processed. To avoid this, we need to be on top of our monitoring and alerting to make sure we anticipate and pre-provision load increases.
At the time of writing, Firehose has released unannounced auto-scaling for Direct PUT configurations to fix this issue.

Our second change was to reduce the amount of data Firehose processed. One option was to aggregate and compress records before sending them to Firehose (something we already have great experience with for Kinesis Data Streams). Unfortunately, this introduced complexity for our downstream readers processing the data after landing in S3 because they had to know the format and support decompression.
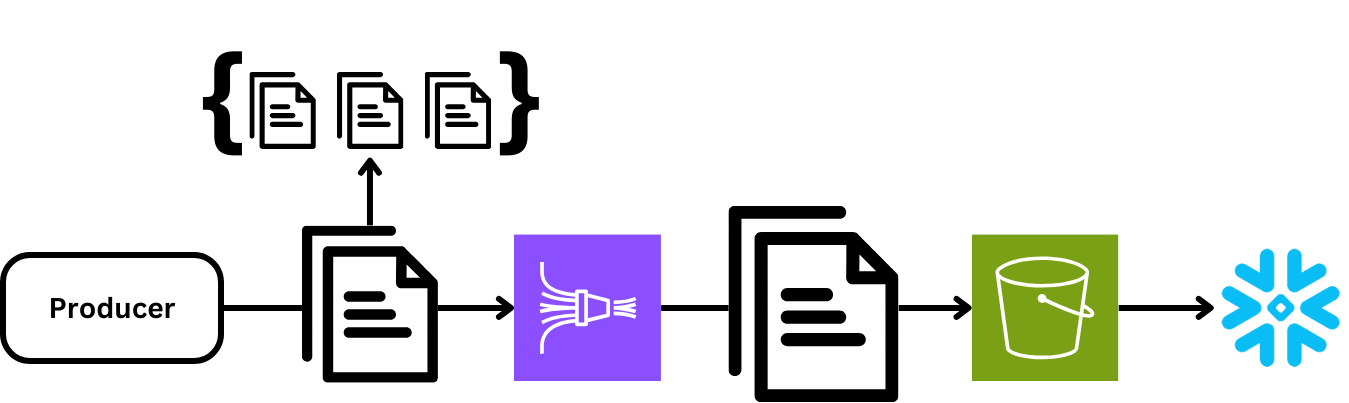
From this we decided we had 2 good options:
- Introduce compression and aggregation to the data we pushed to Firehose.
- Implement our own S3 writer or leverage one of the many open-source alternatives.
Either option would have been a good alternative until Snowpipe Streaming came along.
Snowpipe Streaming
Snowpipe Streaming(opens in a new tab or window), not to be confused with Snowpipe(opens in a new tab or window), is a partially managed solution released by Snowflake intended for the low-latency ingestion of data. Snowpipe Streaming enables low-latency data ingestion by streaming rows directly into Snowflake tables (essentially, streaming blobs to S3), bypassing the need for file staging. Unlike traditional Snowpipe, which loads data from files, this API is designed for real-time data streams like those from Apache Kafka or, in our case, Kinesis Data Streams.
One of the great things about Snowpipe Streaming is that all major data transfers happen between your host and S3, which is free! For those familiar with AWS networking costs, this should be a joyous statement to hear.
This synergy made a lot of sense to us. In our Analytics Pipeline we move data between Java workers using Kinesis Data Streams, reading and writing using the Kinesis Client Library, why push it to an aggregation service, then to S3 as a file and then slurp it into Snowflake? Instead, let’s write it once. The advantage of Snowpipe Streaming compared to a custom solution is that it provides many managed features, such as automated compaction through file migration, exactly once semantics, and a rich roadmap for further development. Additionally, we could rely on the great engineers at Snowflake to solve some of the more complex pieces of buffering and flushing within the client.
The topology of Snowpipe Streaming is quite simple and abstracts away much of the complexity when inserting data. The main challenge is that the interface for inserting data isn’t synchronous. There are a lot of buffers and handshakes to make to guarantee insertion.
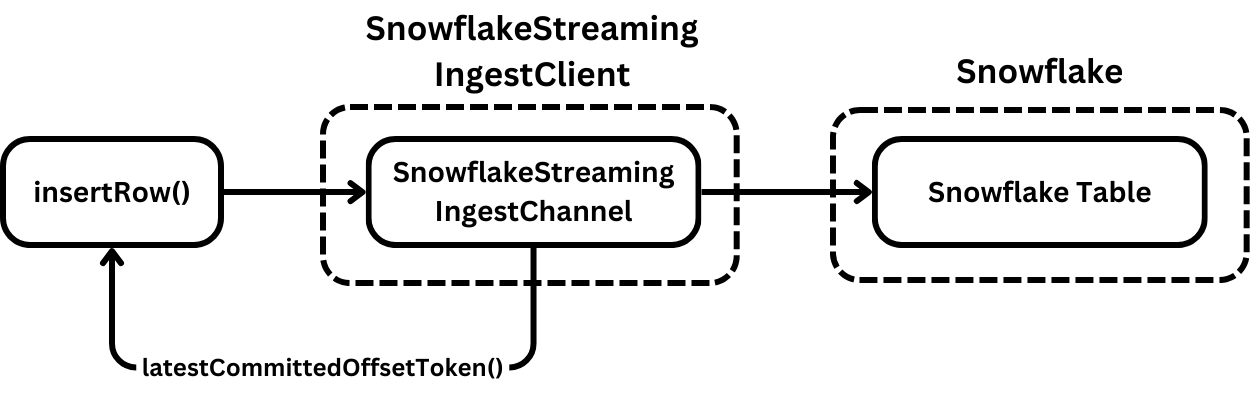
Insertion is managed through channels, where each channel contains an offset token or checkpoint that maintains the greatest point to which a particular logical stream of data has been committed. As rows are inserted into channels through the client, the processor polls the channel for this committed offset to work out its progress. For more implementation information, see the Snowflake documentation(opens in a new tab or window) or view the client source code(opens in a new tab or window). There’s also a great blog post by Yuval Itzchakov(opens in a new tab or window).
You might be wondering how much it costs? Pricing is split into two components:
- A charge per client of 0.01 credits (0.02 USD for standard edition Snowflake) per hour, which is billed in 1-second increments. This is a markup of 11% on top of S3
PutObjectpricing. - A computation cost charged to migrate data from the intermediate format to Snowflake’s optimized format.
Snowflake recommends experimenting by performing a typical streaming ingestion load to estimate future charges. We found the costs extremely reasonable, especially when we applied maximum optimizations. For this blog post, the more interesting piece is the integration between Snowpipe Streaming and Kinesis Data Streams. Snowflake does provide a great connector for Kafka to integrate with Snowpipe Streaming. However, Canva doesn’t use Kafka.
Integrating Snowpipe Streaming with Kinesis Data Streams
To integrate Kinesis Data Streams with Snowpipe Streaming there are a few options:
- Use the Kinesis Client Library (KCL).
- Develop a custom connector that leverages Kinesis APIs.
At Canva, we pride ourselves on pragmatic excellence, and in this scenario, the pragmatic decision was to leverage the KCL to deliver value as soon as possible. In a perfect world, we’d implement a perfect connector, but time is money.
It’s worth noting that Firehose does support Snowflake as a destination using Snowpipe Streaming(opens in a new tab or window), which is a convenient option for those looking to get a project off the ground quickly. Importantly, the Snowflake destination doesn't have a minimum 5 KB record size(opens in a new tab or window), which reduces the costs for small rows dramatically, but when configured, it’s 3 times more expensive than the S3 destination. In our case, we still needed better cost reductions, so we didn’t opt to use Firehose.
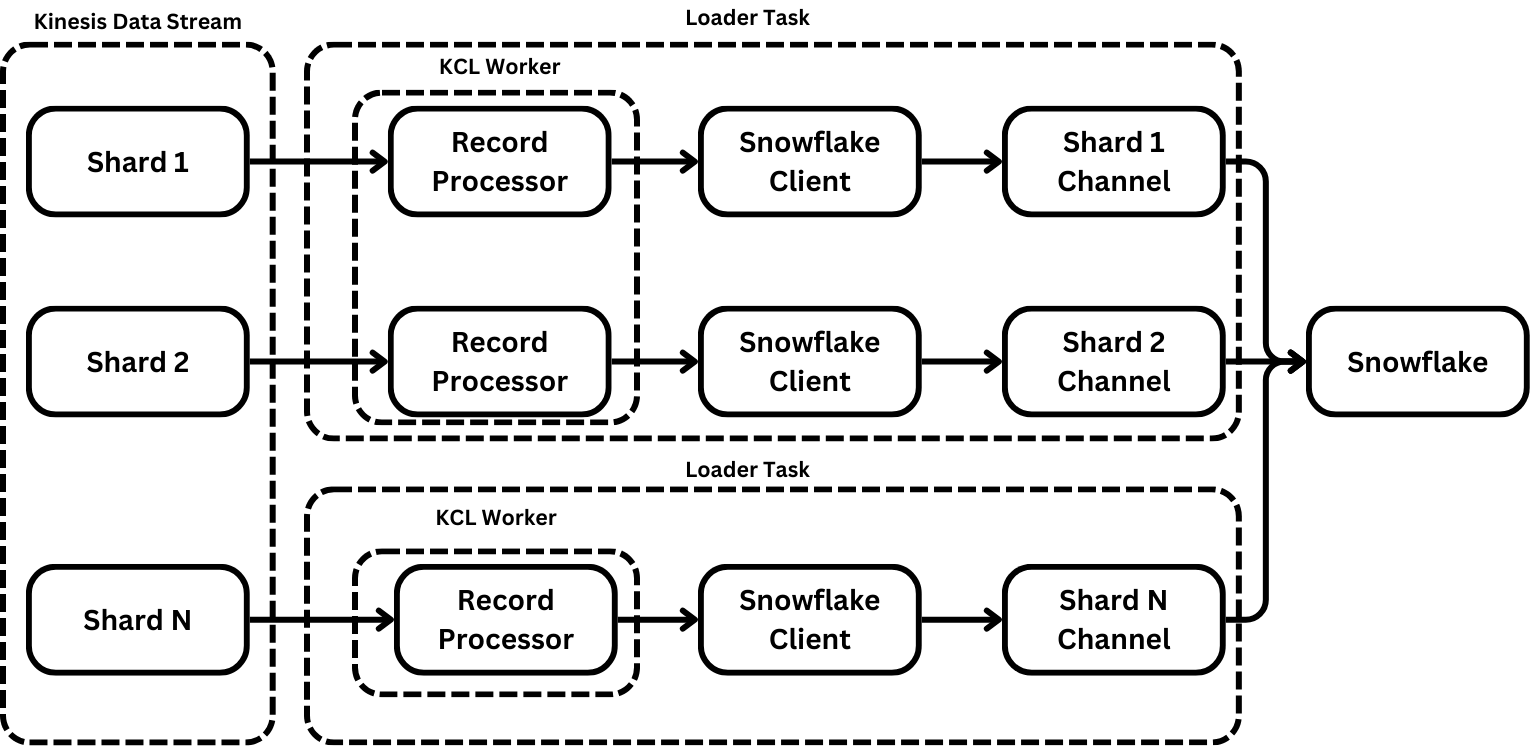
Kinesis Data Streams uses shards to scale and manage data distribution. This matches Snowpipe Streaming’s channel methodology, where one channel maps to a single shard. As each RecordProcessor processes data, it can asynchronously poll the channel for the latest checkpoint and then provide that checkpoint to the KCL.
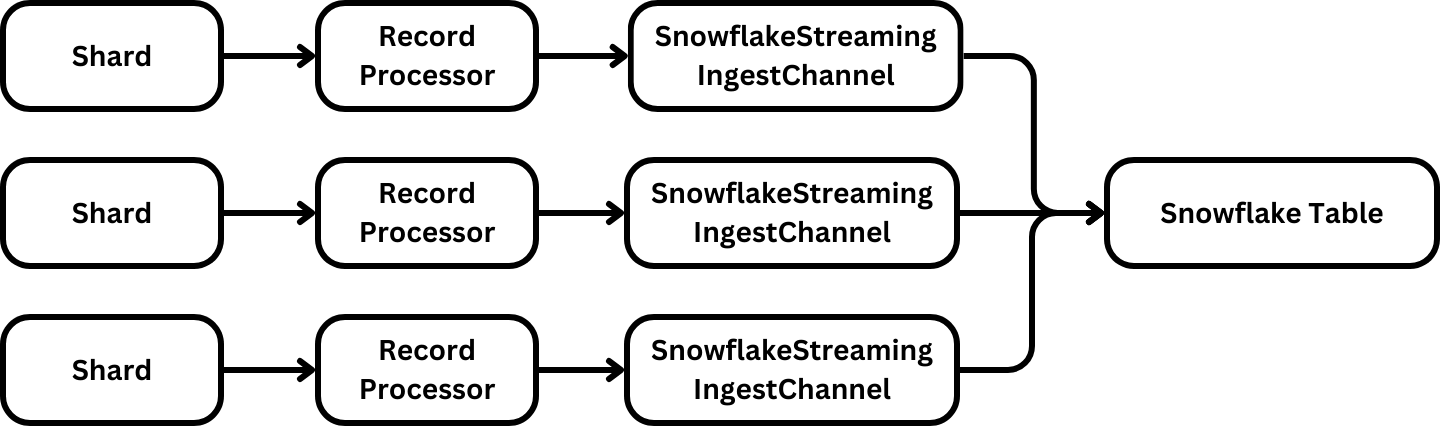
Challenges
The first challenge of integrating Kinesis and Snowflake is dealing with invalidated channels. The main cause of invalidations is that the client or Snowflake can’t maintain its delivery guarantee if it advances the offset token.
Also, when a different client opens a channel, the previous client's channel is invalidated. This is a common occurrence when working with the KCL because load balancing is performed through shard stealing, allowing two RecordProcessors to process a shard simultaneously.
This happens when a new worker starts up and needs to acquire leases on a shard from other workers in the pool. Through a work-stealing algorithm, the new worker acquires a lease and starts processing data. In the KCL, there’s no coordinated handoff between the workers, resulting in two workers processing data simultaneously.
This is problematic because when one channel is invalidated on a client, all channels are invalidated. This is done because of the client’s compaction of channels into blobs. To allow the blobs into the table, the client would need to remove invalid data from the already processed file. Instead, it relies on the caller to be able to restart processing from the latest committed offset token.
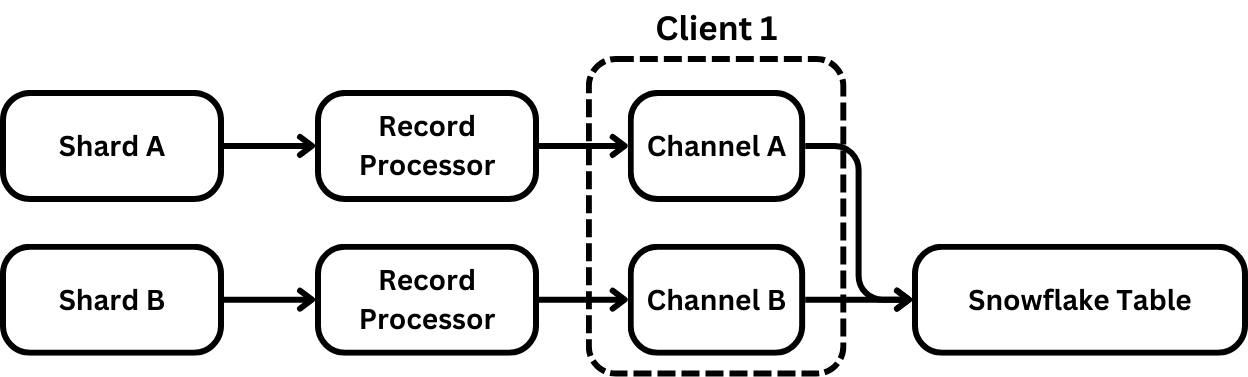
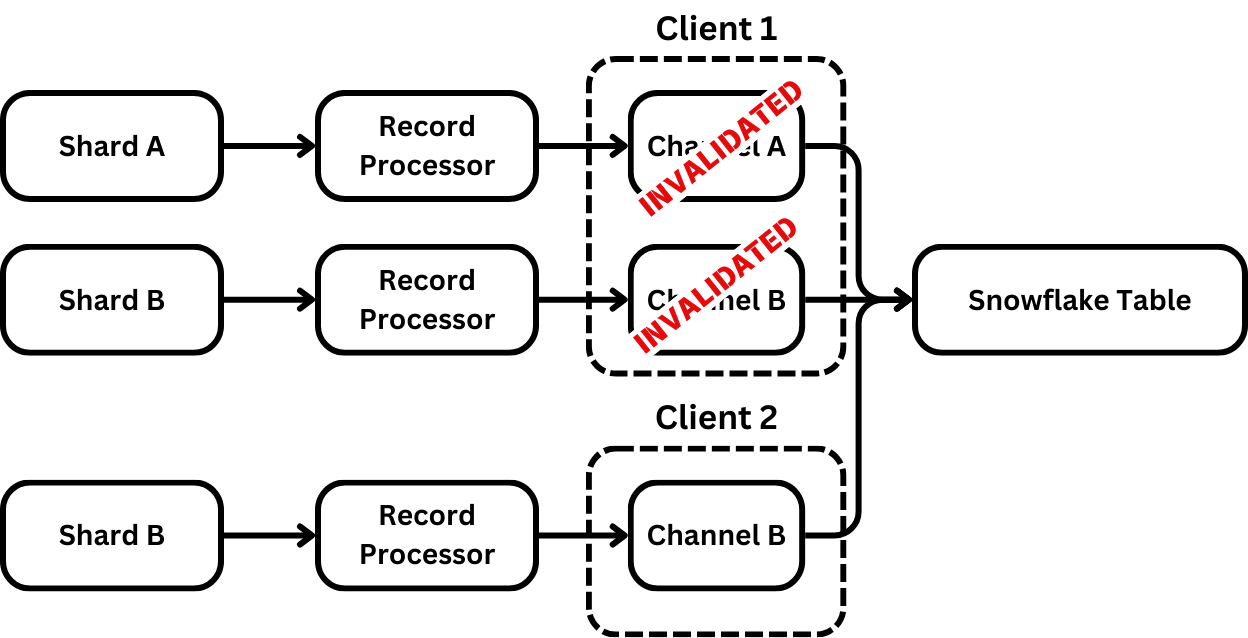
For a custom implementation, this is fine because the processor can move its iterator backward for all channels and pick up at the last committed offset. However, the KCL has no such mechanism. RecordProcessors only advance forward. Ideally, we'd implement our own version of the KCL. But we decided to err on the side of pragmatism and to move forward with an alternative solution.
Instead, we decided it would be easier to instantiate one Snowflake client per shard and, therefore, per channel. However, this comes at a cost because Snowflake charges per client that registers to send data through Snowpipe streaming. It also meant a performance loss because each worker would have many more threads performing duplicated I/O and processing that would’ve previously been optimized through a single client. There’s also a substantial loss of compressibility because smaller batches are compressed.
These disadvantages haven’t added up to enough of a reason to implement our own client (yet). With this solution we don’t experience invalidations for all channels on a single client, improving system reliability.
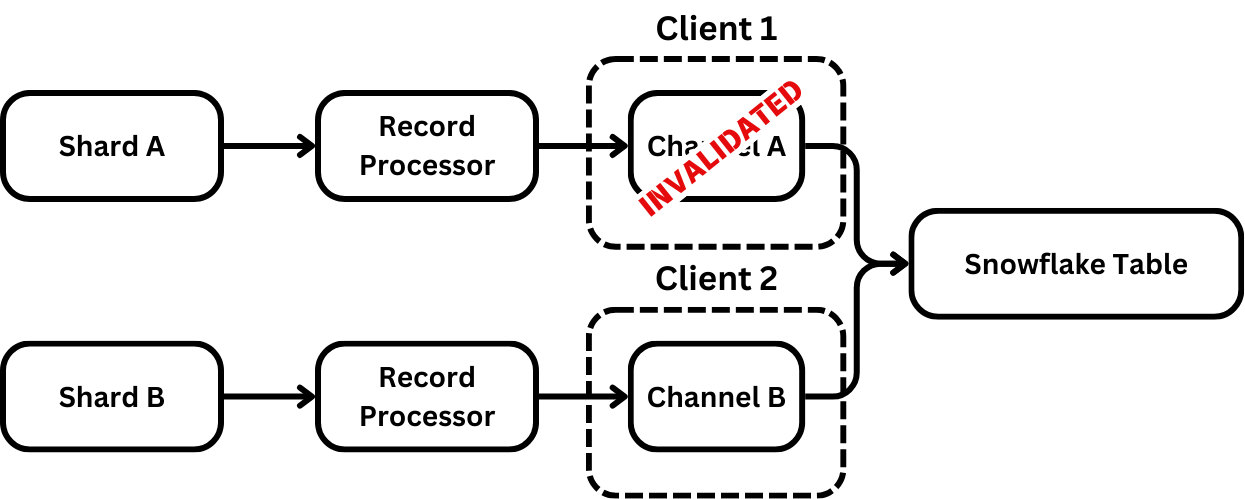
Another issue with channel invalidation, borne out of a lack of restart capability from the KCL, is that even with this isolation, there’s no mechanism in the KCL to remove record processors when they stop processing records. When a channel is invalidated because it was stolen, this works fine because it gets reaped by the KCL after its invalidation. See the previous diagram for how this works.
When a channel is invalidated, not because of being stolen but because of an issue with the channel, this is a problem because there’s no restart mechanism built into the KCL. When a shard becomes unhealthy, there’s no proper way to restart it. Instead, we leverage the LeaseCoordinator(opens in a new tab or window) and allow a record processor to declare itself unhealthy and then drop the lease using the coordinator. This is a bit of a hack and we generally don’t recommend it. This is a capability we’re talking to the Kinesis team about.
Optimize Snowpipe Streaming
To get maximum cost optimization when working with Snowpipe Streaming, you need to choose how quickly you need your data. If you don’t have latency requirements, increase the buffering on your client. In our setup, we use a MAX_CLIENT_LAG of 5 minutes. However, we often don’t hit this and instead rely on the client to flush when its buffers are full.
Also, we highly recommend you use thicker clients to pack more channels onto a single client, which optimizes compression and reduces your per-client cost (we've yet to do this).
Making these changes will reduce your per-client costs because they’re billed per second (at an extremely reasonable 0.01 credits per client per hour). However, the main reason for making both of these changes is that when performing file migration, we assume that the small files problem still applies and that any improvement in file size would reduce costs for file migration as well.
Result
We’ve been running Snowpipe Streaming in production for over 6 months. In that time, we’ve processed over 20.35 PiB of data through the system without significant downtime. We’ve reduced our time-to-query latency to approximately 10 minutes and are on a journey to go even quicker.
This rollout reduced our platform’s cloud spend bill by 45% overall. Through this experience, we’ve realized a new form of data ingestion that is incredibly efficient and cost-effective for delivering data. In the future, we expect the cost to go down further with Snowflake as parameter configuration options like file migration are released and the client's performance continues to improve.

As a result of this work, we’re creating more continuous workloads in Snowflake that process data in minutes instead of hours. We’re heavily leveraging new tools like triggered tasks, Snowflake Streams, dynamic tables, and other concepts that let us move from a batch-oriented world to a more continuous one without having to take on the burden of deploying stream processing. We currently use these tools in our deduplication pipeline, making responding to data incidents and delivering fresher data easier.
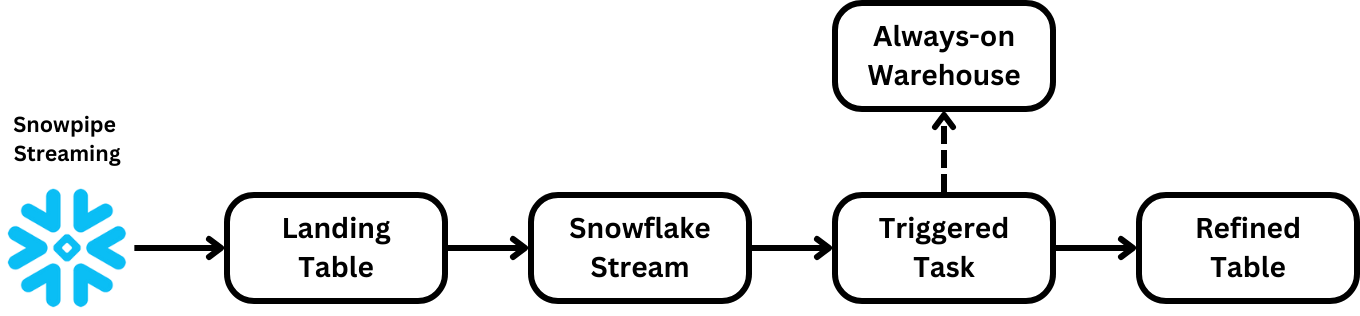
The roadmap for Snowpipe Streaming also looks great. As a platform, we’re very interested in Iceberg, schema evolution, and how we can simplify landing data for end users. Stay tuned as we build out our continuous data platform.
Thanks
Many thanks to the entire Product Analytics Platform team for helping to build a world-class platform. In particular, I’d like to thank James Robinson(opens in a new tab or window) for his assistance with the project, as well as Arthur Baudry(opens in a new tab or window) and Guy Needham(opens in a new tab or window) for their support. I would also like to thank Marko Slabak(opens in a new tab or window) for putting the success in customer success with one too many late nights discussing optimal implementation and to the entire Snowpipe Streaming team for developing a great product.


