Machine Learning
Image replacement in Canva designs using reverse image search
Qualitative comparison of image embedding models to power a scalable similar-image replacement system for Canva designs.
Maintaining a high-quality library is key to creating a seamless design experience for our users. As part of the quality process, swapping an image in a template with another image sometimes becomes necessary. For example, if a third-party media library partnership expires, anywhere we've used their content in the library needs to be replaced. As expected, this is a lengthy process involving extensive manual resources. So naturally, the question arises, can we automate solving it?

Image similarity
Image replacement is a textbook application for reverse image search(opens in a new tab or window). This kind of application needs to take an input image and respond with the most similar-looking images in the database. Similarity, however, is quite subjective, so we decided to model image similarity with a hierarchy.
First in the similarity hierarchy is the image subject. If you have a photo of an apple and are looking for similar images, it's most important to find another picture of an apple. Secondly, there are other obvious, finer-grained details, such as color and tone. A red apple should be similar to other pictures of red apples. After this comes things like subject positioning in the frame, the image background, and the emotion conveyed. These things are less critical but essential for a perfect replacement image.

In addition to these considerations, a crucial part of design, though not necessarily covered by the definition of image similarity, is the image aspect ratio. In a template, if you want to swap out an image with a 3:4 aspect ratio, you want another image with the same ratio.
Design considerations and requirements
Before jumping ahead to a solution, it was important for us to establish the essential requirements:
- Given an input image, suggest the most similar looking, intellectual property (IP)-safe images available.
- Search across more than 150 million images.
- Stay up-to-date with changes in our media library.
- Filter on metadata fields, such as aspect ratio.
- Reusability and extensibility for other applications.
With these requirements in mind, we could investigate if any existing internal solutions could be repurposed to suit our needs.
The first possibility was to reuse our recommendation engine, which can suggest images a user might want to use in their design. However, recommendations aren't ranked solely on similarity but also on factors like popularity and design context. Therefore, the images wouldn't be similar enough to suit our requirements.
The next option was to use our perceptual hash system. Given an image, this system can return potential duplicate images. Unfortunately, duplicate images and similar images are not the same thing. Duplicate images are considered too similar for our use case. If we're removing an image from a template, it's likely that the duplicate of this image shouldn't also exist, meaning that it won't always return a result for an input image.
Another option was to search images using a text-to-image search. This search typically matches images by their metadata and describes the existing search pipeline at Canva. This wasn't appropriate for our use case because although metadata often retains key features such as subject, it doesn't capture nuanced visual features like the number of subjects, key colors, and image emotion.
Lastly, we considered using AI-generated images as replacements. We ruled out this option because generated images are not guaranteed to be IP-safe.
Left without a suitable solution to reuse, we had no choice but to build an image-to-image search, based on image similarity.
Image embeddings
The first step to consider was how we wanted to represent an image, which would greatly affect our next step, deciding how to search images. Given that we already ruled out a textual representation of images (text-to-image search), the remaining direction was visually representing an image as a high-dimensionality vector, otherwise known as image embeddings. We extract these embeddings from machine learning models trained on image-related tasks. Luckily, computer vision(opens in a new tab or window) is a heavily studied field in computer science, so instead of developing a new solution, we decided to explore the current state-of-the-art options. We picked 5 high-performing models to experiment with:
- DINOv2(opens in a new tab or window)
- CLIP(opens in a new tab or window)
- ViTMAE(opens in a new tab or window)
- DreamSim(opens in a new tab or window)
- CaiT(opens in a new tab or window).
First, we selected 50,000 images from our library. For each model, we generated embeddings for each image and stored them in an in-memory vector database(opens in a new tab or window) using the Faiss(opens in a new tab or window) library. Then, we selected a sample of 200 images and found the nearest 3 neighbors for each model. Engineers and designers manually viewed the nearest neighbors, and using the image similarity hierarchical model described previously, decided on the most suitable model.
As well as these approaches, we tried sending an image to GPT4o(opens in a new tab or window) with a prompt to describe it, using the textual description to search against the CLIP vector database because CLIP supports image-to-image and text-to-image use cases.
The following are the results from a single input image for each approach, with the most similar image from each model. For more examples, see Additional model comparison examples.

Each model produced impressive results. Description + CLIP was the least successful because it failed to capture many desirable similarity aspects, such as secondary subjects and most coloring or tones seen in images. In the end, in our evaluation across a large number of images, we concluded that the most suitable model for our use was DINOv2.
Vector database
Now that we knew we wanted to use image embeddings, we had to decide on the vector database approach because that's the best way to store and query high-dimensionality vectors. Our first decision was between using an in-memory approach or an external vector database.
For the in-memory approach, we'd need to ingest the entire image library of 150 million images, and embed and wrap them in an index before persisting them in memory. This would require a costly, dedicated machine with a huge amount of RAM, which wouldn't align with Canva's recommended design approaches. Finally, significant fluctuations in the media library size would require migrating to a server with more RAM, increasing the maintenance costs even more.
By comparison, we can interact with an external vector database in much the same way as a typical persistence solution, updating in real-time with any media library changes at a much cheaper cost. Support for metadata fields and field filtering is also possible, which is crucial for operations like filtering on image aspect ratio. We decided on this option, and, for time and cost reasons, chose a third-party vector database instead of building our own.
Results
Overall, the photo search results were impressive but underwhelming for graphic replacements. The system was strong in preserving subjects, background, and general emotion in photos, but was weaker in images containing text, symbols, or non-realistic imagery like cartoons or drawings.
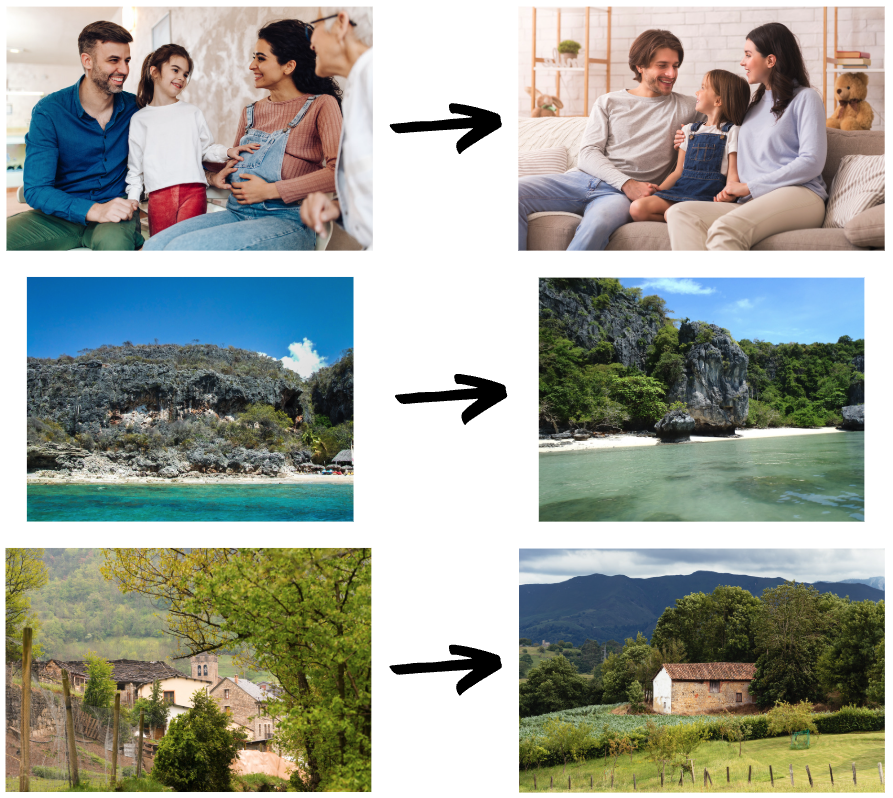
The following are some examples of strong replacements.
The following are some examples of weaker replacements.
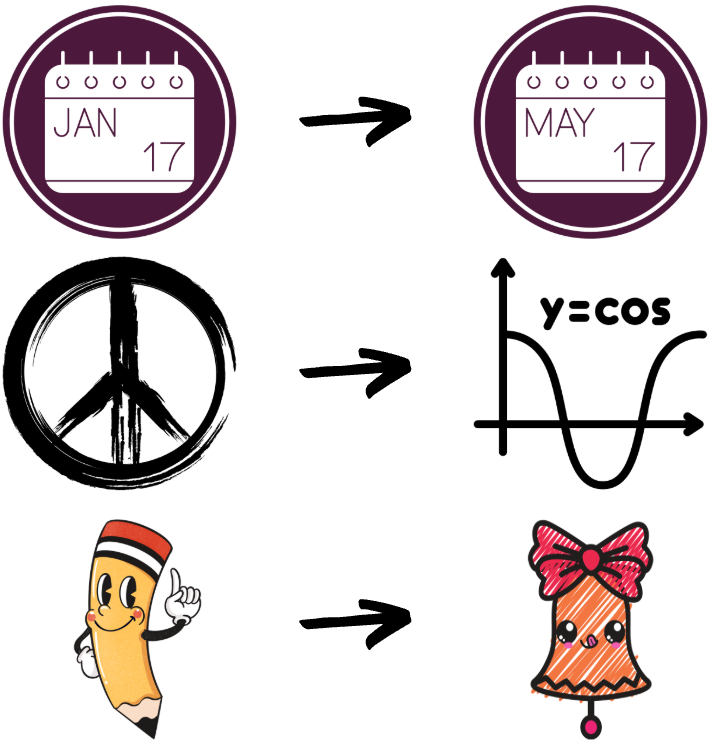
There are two likely reasons for these weaknesses. First, DINOv2 was trained on a custom-curated dataset called LVD-142M. While this dataset is closed source, many of the open source datasets that make up its composition are from photographs instead of cartoons or symbolism-heavy images. Secondly, DINOv2 wasn't trained for symbol recognition tasks, but instead more general object, texture, and scene categorization arising from training on masked portions of images.
Therefore, without customizing the original DINOv2 image embedding approach, we obtained strong results on photos, which is a significant aid to professional designers needing this feature.
User interface
With the system now live, we can integrate the feature into the Template Assistant, which is the menu we show to Canva's template designers. A design is linted for violating media and highlighted, and the top 8 similar images are displayed to designers. Upon selection, similar images are swapped out with the image in the frame. We can forward the design for human review and republishing back into the template library, creating a human-in-the-loop system for quality control. The following image shows the user interface with reverse image search suggestions displayed in the right-hand panel.
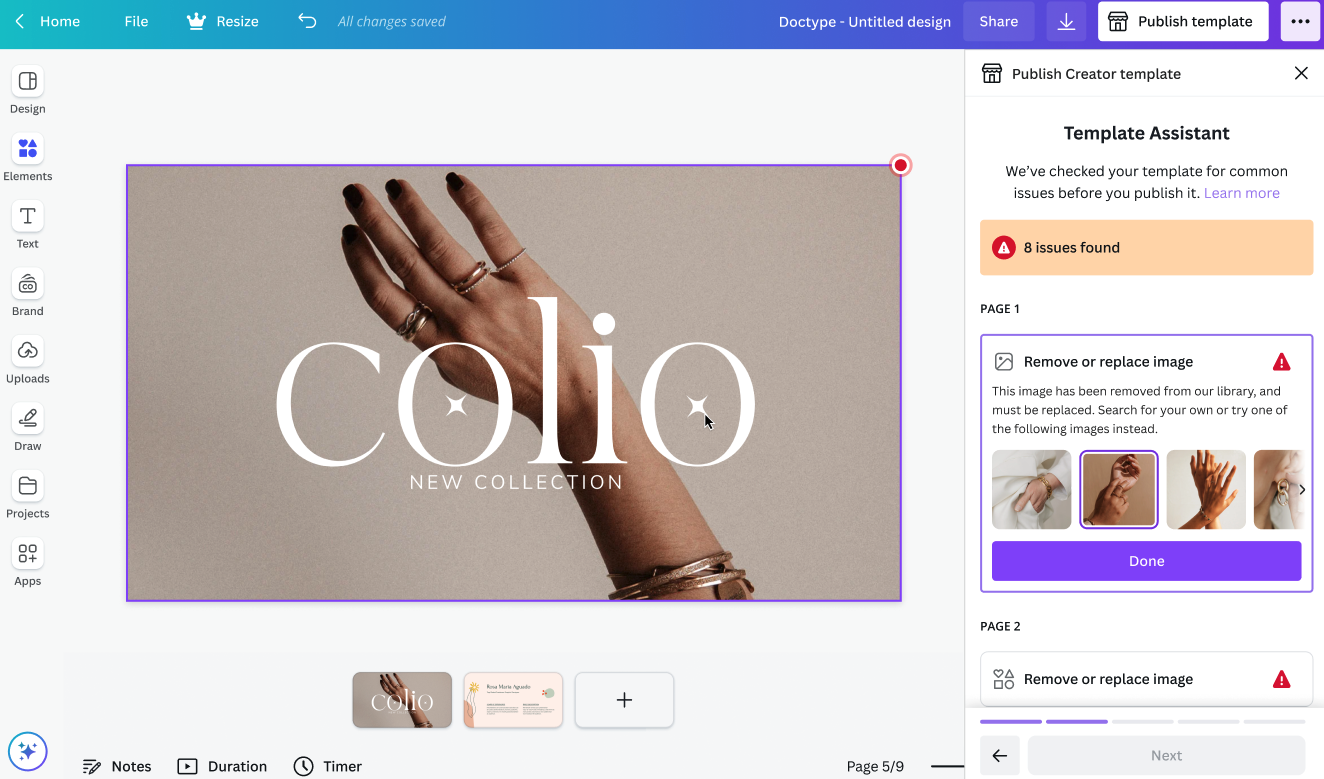
Initial pilots by professional designers showed a 4.5x increase in the speed of image replacement when using the replacement suggestions compared to a regular search. For cases with poorer results, like cartoons and symbolic-heavy imagery, users can select from several suggestions or bypass them entirely using Canva's regular search functionality.
Future work
The system was definitely of sufficient quality for a minimum viable product (MVP), but there are many areas we can improve, such as images containing text. One idea is to detect any symbols or text in an image before storing it in the database and recording these as metadata fields in the vector database. Then, for a new input image, we could match any detected text or symbols against existing text metadata in the vector database.
For example, if the image contains the text 'January', we can store this text in the database along with the image in a 'text' field. Then, when we supply an input image, symbols and text are detected. If present, we can filter the vector database results down to equivalent or closely matching text using an approach like substring matching. If this method is too strict and replacements are poor, it might be necessary to store related, categorical metadata instead, like a taxonomy. For example, we could store 'January' as a 'date and time' category. It's even possible to store both pieces of metadata and try to filter on 'January' first and, if we don't get good results, widen the search to the 'date and time' category.
Conclusion
We're pleased to share that this approach to reverse image searching is helping to maintain a high-quality image library for our 200 million users. As Canva continues to scale, it's exciting to see our innovative applications in backend engineering and machine learning applied to keep our product valuable and our users happy.
Additional model comparison examples


Acknowledgements
Huge thanks to Ben Alexander(opens in a new tab or window) for being my mentor in machine learning, as well as Jonatan Castro(opens in a new tab or window), Neil Sarkar(opens in a new tab or window) , and Minh Le(opens in a new tab or window) for helping shape the decisions relating to the backend. Thanks also to the rest of the Content Enrichment Team, including those who've recently moved on to new teams. Another big thank you goes to Ben, Jason Yin(opens in a new tab or window), Jarrah Lacko(opens in a new tab or window), Vishwa Vinay(opens in a new tab or window), Maggie Xu(opens in a new tab or window), Jaime Metcher(opens in a new tab or window), and Grant Noble(opens in a new tab or window) for reviewing this blog post.
Want to work on powering the content engine at Canva? Join us!(opens in a new tab or window)