Engineering Practices
How we build experiments in-house
Experimentation and experiment analysis are vital procedures at Canva to safeguard the customer experience.

Experimentation is an invaluable decision-making tool, and at Canva, it’s a pivotal step in our product development process to quickly test ideas, measure impact, and safeguard the customer experience of over 100 million monthly active users. We split our experimentation platforms into 2 core components:
- Experiment setup: Creating feature flags and assignments.
- Experiment analysis: Measuring the impact of the change.
In this blog post, we will dive into how the second component, experiment analysis, has evolved over the last few years to support a 10x growth in data scientists and become a central tool in Canva’s data stack.
Background information
At Canva, experimenting with our product has always been part of our journey. However, it wasn’t until 2019 that our data science specialty developed the first version of our experiment analysis framework: a Python package where any data scientist could define shared metrics and create analysis configurations. We could compute the results and view them through a command line interface.

We immediately had one standardized way to calculate and interpret results across the company. Additionally, the package automatically calculated guardrail metrics, letting us monitor an experiment's impact on company-wide goals, such as active users or revenue.
This was an amazing first step, but we quickly discovered that sharing screenshots through Slack or Confluence was cumbersome. We captured the results at a point in time, and data scientists had to manually re-process the results whenever a stakeholder asked.
To solve this issue, we created a Django web app to schedule daily updates and provide an interface to share analysis results across the company. We were still creating and storing metrics and analysis configurations in the Python package, but we were now persisting results in a database. Stakeholders could navigate to a UI to see up-to-date results whenever they wanted.
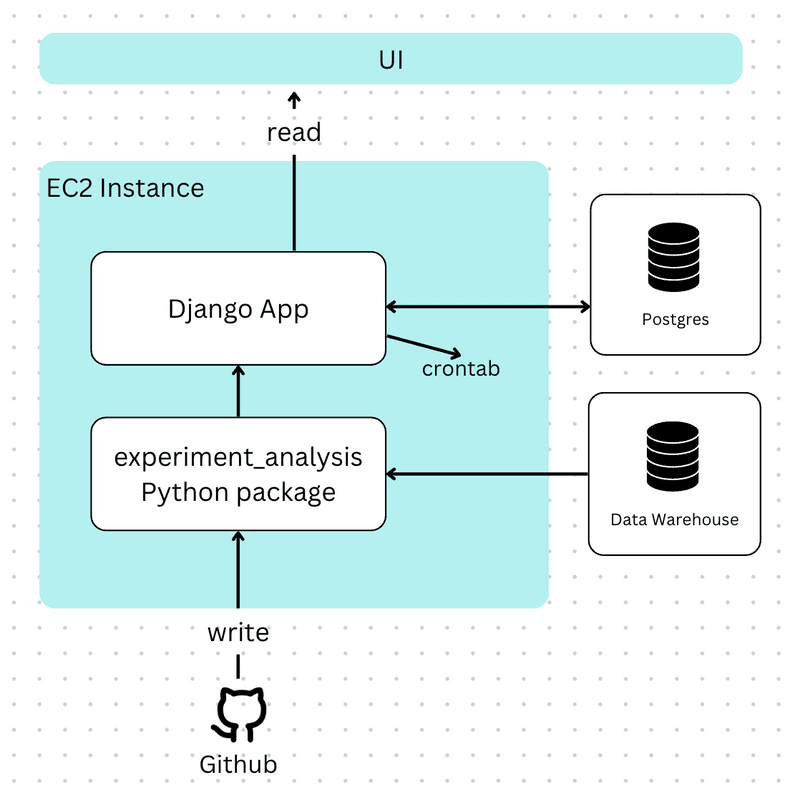
How we presented results on the command line worked pretty well so far, so the way we displayed them in the web app wasn’t drastically different.

Over time, to support our growing China product (canva.cn) and abide by data regulations, we deployed a second instance of the Django app to run in China. Having 2 apps meant that for experiments launched to both canva.com and canva.cn, stakeholders had to visit both apps to view results. Clearly, this wasn’t an ideal situation.
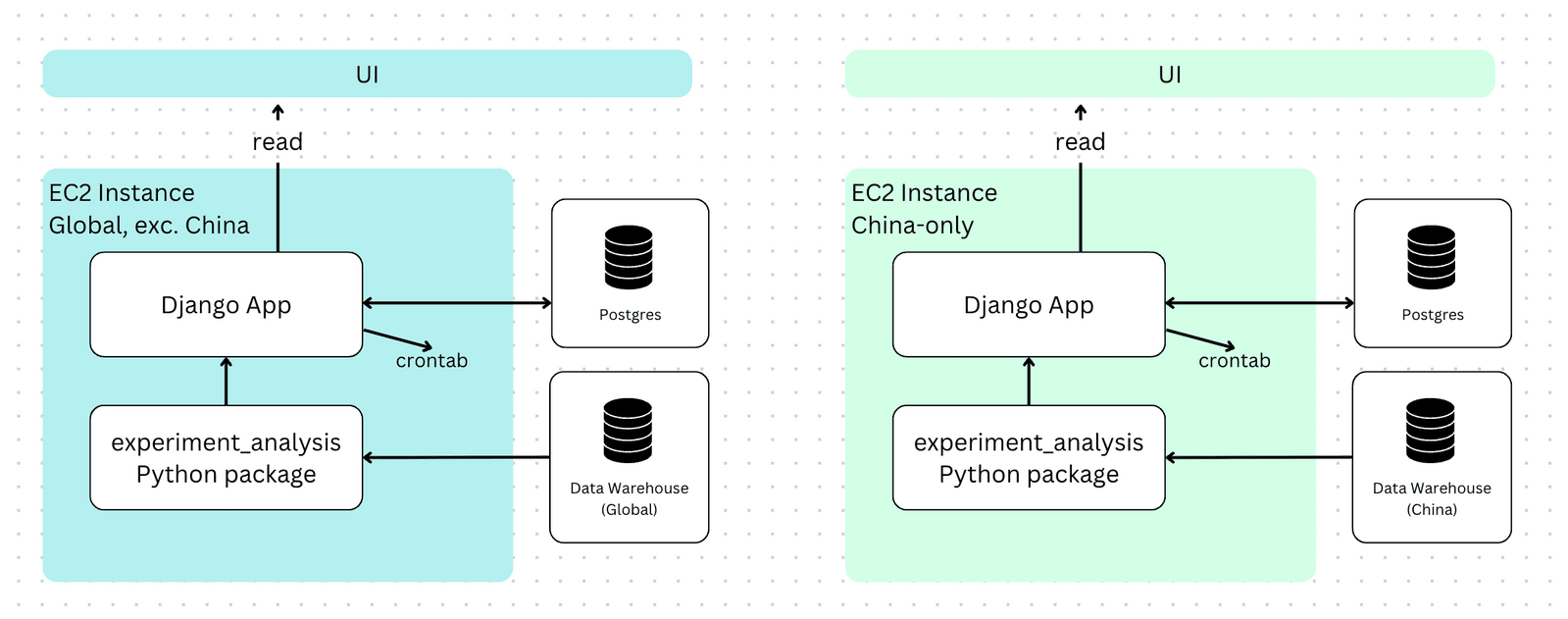
People were starting to feel the growing pains of this system:
- Data scientists spent a lot of time on data entry and analyses configuration. Only those with the right data warehouse credentials could validate and run ad hoc analyses.
- Engineers and product managers couldn’t self-serve and explore why a particular metric wasn’t performing as expected. Instead, they had to meet with their data scientist (if they were lucky enough to have one) and iterate on the data together.
- Onboarding new data scientists was time-consuming and difficult. They had to be familiar with command line tools, GitHub, and YAML file formatting. Incorrectly formatted YAML files meant they also had to learn to read and debug Python error messages. It often took months for a new data scientist to feel comfortable conducting experiment analyses.
- The scale of Canva's growth meant that the number of analyses continued to grow, straining the system such that results weren’t always up-to-date. Stakeholders were frustrated because they felt blocked by data. Data scientists were frustrated because they had to calculate results outside the platform to enable faster decisions.
Trust in the platform was eroding.
Evolution - Handing it over to Engineering
To this point, the experiment analysis framework had been built and maintained by data scientists independently of our in-house feature flagging and assignment product, Feature Control.
It became clear that to elevate Canva to be a world-class data-driven organization, we needed experiment analyses that were reliable, trusted, and accessible to anyone. So, we passed the framework over to a dedicated engineering team to rewrite and integrate it into Feature Control.
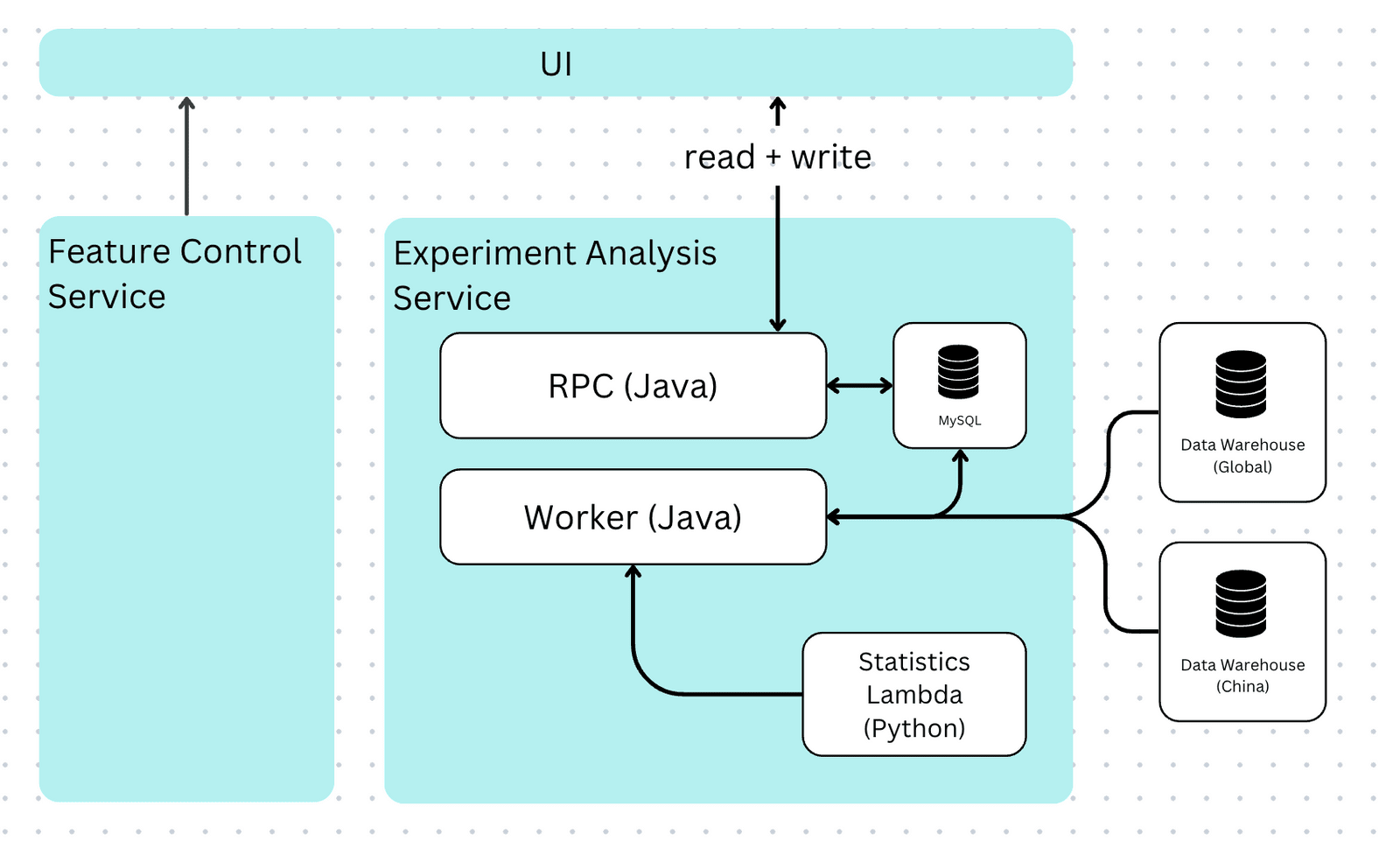
The rewrite resulted in the following improvements:
- We create and run analysis configurations on demand through an interface every Canvanaut can access. Anyone in the company can run an experiment analysis and explore their results.
- The entire experimentation user flow, from creating feature flags and assigning users to new features, to looking at the impact for Global and China users, are all in one place. This gives Canvanauts one less tool to worry about and ensures that all Canva users receive the same great product experience.
The new system has many technical highlights too. The first was packaging up experiment statistical models into a Python library, deployed as an AWS lambda. This worked well because Python is inherently superior for statistical modeling, making it easy for data scientists to apply changes to production models. A nice side effect of using a lambda is that it exposes an API for users to call and use for ad hoc analyses outside our platform.
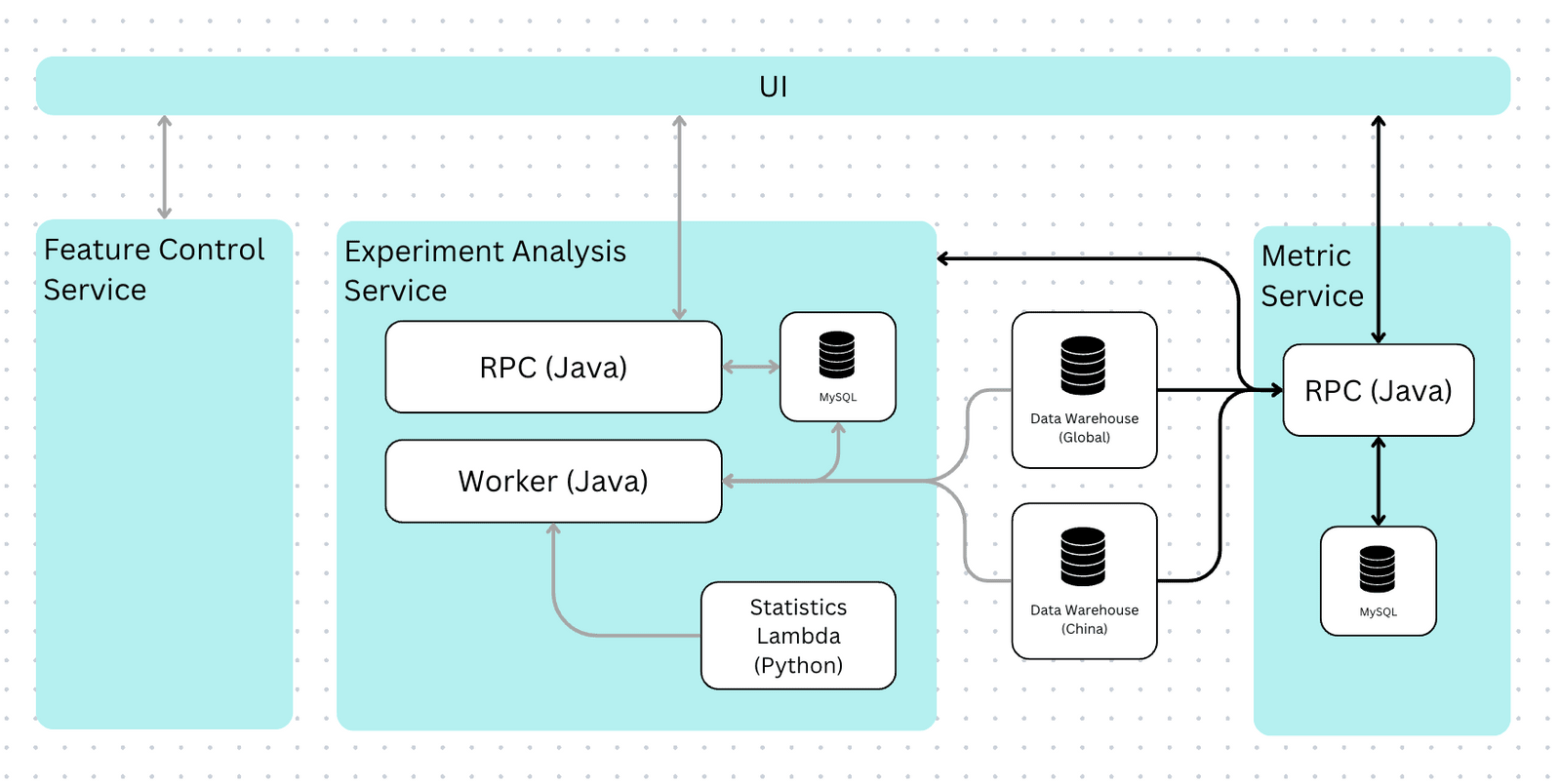
This new architecture also looks like and is written to the quality of a standard Canva product service. It uses the same languages and infrastructure (Javascript, Java, and MySQL), complete with alerts and an on-call roster to ensure minimal downtime.
We also released an education program on the theoretical and practical aspects of experimentation, such as understanding our statistical models, decision-making, and debugging problems. This program was instrumental in empowering Canvanauts to self-serve their data issues and resulted in a drop of over 50% in help requests in our team Slack channel.
Our current architecture
So far, we’ve only built half the foundation of a great experiment analysis platform. The analysis configuration components, such as metrics, are still defined using partial SQL snippets, which we want to write in a very specific way. SQL snippets are flexible and allow quick new metric construction, and worked when data scientists configured the experiment analyses. However, they’re error-prone and almost impossible for non-technical users to write for non-technical users, resulting in overly complex and statistically invalid metrics. SQL snippets don’t scale.
In our most recent milestone, we wanted to make experiment analyses accessible to anyone and encourage everyone to experiment using best practices. To do this, we completely redesigned how users create their experiment analysis components to have a point-and-click interface that abstracts SQL away from most user flows. This approach ensures all metrics are consistent, correct, and statistically valid.
On a technical level, we store and manage these components in a separate microservice. This lets us easily use them in other future applications, such as ad hoc analyses or business intelligence tools.
Final thoughts and where to from here
The experimentation platform at Canva has undergone an incredible transformation in the last few years, and we’ve only just begun. We're focused on continuing to make experimentation accessible to everyone at Canva. Some of our upcoming projects include streamlining the now-fragmented workflows with experiment setup and experiment analyses, and further improving the learnability of the experiment results within the platform.
Acknowledgements
A big thank you to the current Experiments team for making huge improvements in democratizing experiment analysis. In particular, thanks to the original Feature Control team engineers: Dillon Giacoppo(opens in a new tab or window), Kris Choy(opens in a new tab or window), Richie Trang(opens in a new tab or window), Will Zhou(opens in a new tab or window), Tristan Marsh(opens in a new tab or window), and Shane Morton(opens in a new tab or window) for rebuilding the engineering foundations of our experiment analysis platform. Additionally, a special thank you to our data science specialty, who have authored, maintained, and educated the engineering team and broader company on our experiment analysis framework. Your contributions have been invaluable in shaping and advancing our capabilities.