Post incident review
Canva incident report: API Gateway outage
An incident report for the Canva outage on November 12, 2024.

High-level summary
On November 12, 2024, Canva experienced a critical outage that affected the availability of canva.com(opens in a new tab or window). From 9:08 AM UTC to approximately 10:00 AM UTC, canva.com was unavailable. This was caused by our API Gateway cluster failing due to multiple factors, including a software deployment of Canva's editor, a locking issue, and network issues in Cloudflare, our CDN provider.
This report details the root cause, timeline of events, how we mitigated the outage, and the steps we're taking to prevent similar incidents in the future. We're sharing this report publicly to demonstrate our commitment to transparency, accountability, and continuous improvement.
Background
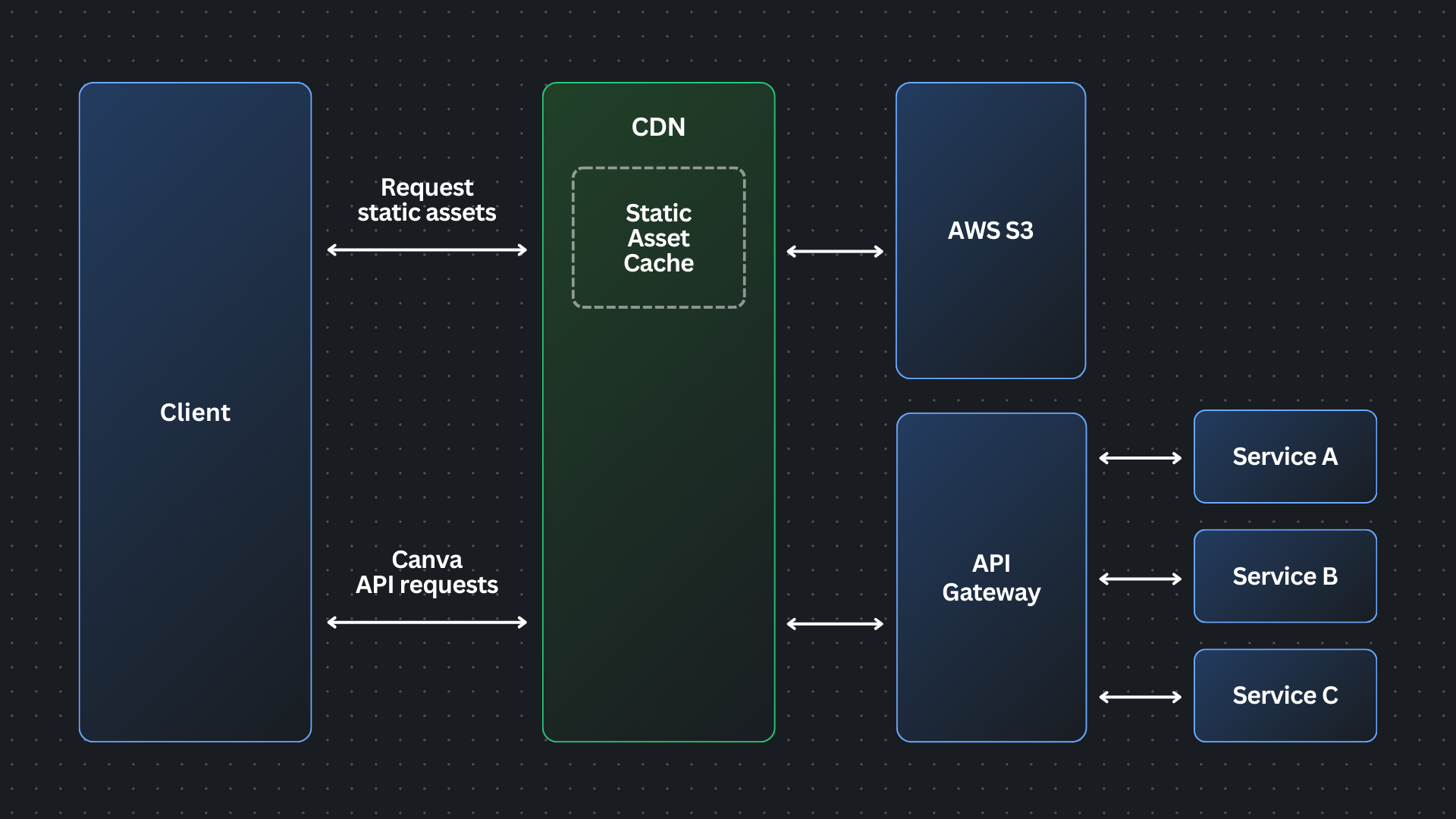
Canva's editor is a single-page application that's deployed multiple times a day as part of our continuous deployment pipeline. During each of these deployments, over 100 new static assets, including JavaScript files essential for key features like the object panel, are bundled and published to an AWS S3 bucket.
Client devices then fetch these assets through our CDN provider, Cloudflare, using a tiered caching system(opens in a new tab or window). When a user visits canva.com, Cloudflare first checks the local data centers for cached content. If the requested files aren't available locally, the local data centers request the content from regional or upper-tier data centers, and if necessary the upper tier retrieves the files from Canva's origin S3 bucket.
After loading the static assets, the editor's JavaScript makes API calls to Canva's API Gateway to continue loading the editor.
The API Gateway, a critical component of Canva's infrastructure, serves as the entry point for all API requests and handles a range of cross-cutting concerns, such as authentication, authorization, rate limiting, etc. The API Gateway is built on Netty(opens in a new tab or window), a networking library that powers our standard Java microservices stack. The API Gateway runs as an autoscaled group of tasks on Amazon ECS.
The incident
At 8:47 AM UTC, a new version of Canva's editor page was deployed and client devices began fetching the new static assets. At the same time, the network path between Cloudflare's Singapore (SIN) and Ashburn (IAD) locations experienced network latency issues. The additional network latency was reflected in the 90th percentile time-for-first-byte increasing by over 1700%. The fetch of one particular asset was affected to the point where it took 20 minutes to complete.
“The network issue was caused by a stale rule in Cloudflare's traffic management system that was sending user IPv6 traffic over public transit between Ashburn and Singapore instead of its default route over the private backbone. This rule was preventing Cloudflare's automation from taking preventative actions from routing around the packet loss because the rule prevented alternative paths from being considered. The packet loss over this path reached about 66% at peak during the impact window. Cloudflare has removed the traffic management rule that caused requests to go over the potentially lossy paths, to ensure service will remain of good quality to Canva in the future.”
— Cloudflare
The affected asset was a JavaScript file (chunk) responsible for displaying the editor's object panel. As a result, for many users, particularly users in Asia, the object panel remained in a perpetual loading state.
The object panel loading normally (left) and what users saw when it failed to load (right).
To understand what caused the single chunk to fail to load in a timely manner, we need to explain how Cloudflare fetches assets from the origin.
Cloudflare employs a mechanism called a cache stream(opens in a new tab or window) (referred to as Concurrent Streaming Acceleration) to optimize caching performance. This feature consolidates multiple user requests for the same asset into a single request, progressively serving the response body as it becomes available.
Normally, an increase in errors would cause our canary system to abort a deployment. However, in this case, no errors were recorded because requests didn't complete. As a result, over 270,000+ user requests for the JavaScript file waited on the same cache stream. This created a backlog of requests from users in Southeast Asia.
At 9:07 AM UTC, the asset fetch completed, and all 270,000+ pending requests were completed simultaneously. With the JavaScript file now accessible, client devices resumed loading the editor, including the previously blocked object panel. The object panel loaded simultaneously across all waiting devices, resulting in a thundering herd of 1.5 million requests per second to the API Gateway — 3x the typical peak load.
The spike in traffic, combined with a performance regression discussed below, resulted in a quick build-up of backlogged requests. Because the API Gateway tasks were failing to handle the requests in a timely manner, the load balancers started opening new connections to the already overloaded tasks, further increasing memory pressure.
The growth of off-heap memory caused the Linux Out Of Memory Killer to terminate all of the running containers in the first 2 minutes, causing a cascading failure across all API Gateway tasks. This outpaced our autoscaling capability, ultimately leading to all requests to canva.com failing.
Telemetry bug
Prior to this incident, we'd made changes to our telemetry library code, inadvertently introducing a performance regression. The change caused certain metrics to be re-registered each time a new value was recorded. This re-registration occurred under a lock within a third-party library.
The API Gateways use an event loop model, where code running on event loop threads must not perform any blocking operations. Under the additional load, the lock contention incurred from the telemetry library significantly reduced the maximum throughput a single API Gateway task could handle.
Although the issue had already been identified and a fix had entered our release process the day of the incident, we'd underestimated the impact of the bug and didn't expedite deploying the fix. This meant it wasn't deployed before the incident occurred.
Timeline of events
How we mitigated the incident
During the incident, we focused on stabilizing Canva's systems as quickly as possible, while minimizing further disruption to users. Below is an outline of our key mitigation steps:
-
Scaling API Gateway tasks: As API Gateway tasks were terminated, our autoscaling policies attempted to bring up new tasks as replacements. These new tasks became overwhelmed by the ongoing traffic spike as soon as they were marked healthy and were promptly terminated. We attempted to work around this issue by significantly increasing the desired task count manually. Unfortunately, it didn't mitigate the issue of tasks being quickly terminated.
-
Traffic blocking at the CDN level: At 9:29 AM UTC, we added a temporary Cloudflare firewall rule to block all traffic at the CDN. This prevented any traffic reaching the API Gateway, allowing new tasks to start up without being overwhelmed with incoming requests. We later redirected canva.com to our status page to make it clear to users that we were experiencing an incident.
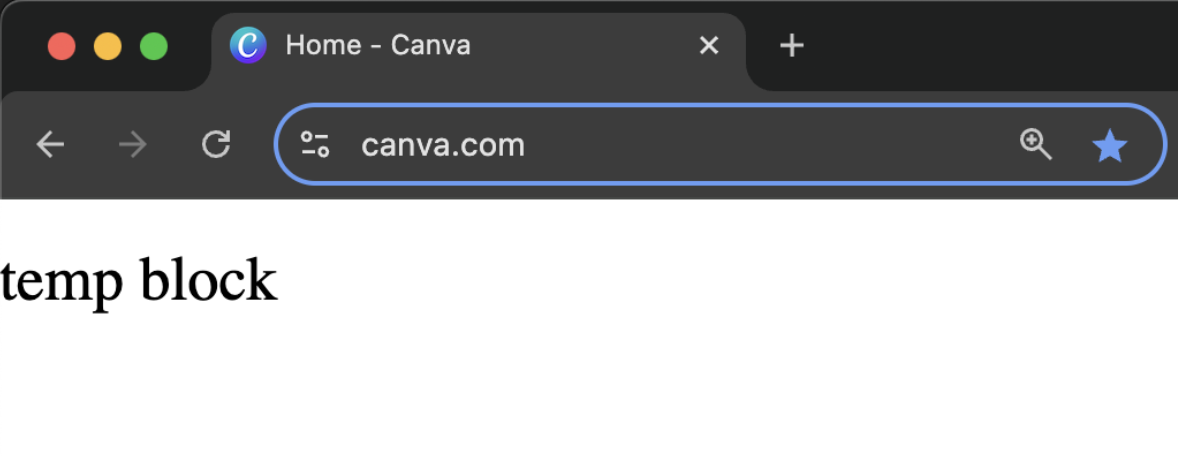 What users saw when we initially blocked traffic, prior to setting up a redirect.
What users saw when we initially blocked traffic, prior to setting up a redirect. -
Gradual traffic restoration: Once the number of healthy API Gateway tasks stabilized to a level we were comfortable with, we incrementally restored traffic to canva.com. Starting with Australian users under strict rate limits, we gradually increased the traffic flow to ensure stability before scaling further.
Action items
Following the incident, we undertook immediate and long-term actions to address the root causes and contributing factors. Our goal was to stabilize the platform, improve system resilience, and make sure that similar incidents are less likely to occur in the future.
Incident response process improvements
- Runbook for traffic blocking and restoration: We're building a detailed internal runbook to make sure we can granularly reroute, block, and then progressively scale up traffic. We'll use this runbook to quickly mitigate any similar incidents in the future.
- User communication: When canva.com is unavailable, we'll make sure users receive a more informative error page.
Increased resilience of the API Gateway
- Task configuration: We've increased the baseline number of tasks, and the memory allocation for each task, for API Gateway. This provides us additional headroom for handling traffic under abnormal conditions.
- Load shedding: We're implementing additional load shedding rules in the API Gateway, focusing on reducing the risk of failure under similar traffic patterns.
- Load testing: We'll introduce regular load testing to the API Gateway to make sure it can handle similar scenarios, so we can continuously make changes without issues.
Fix the telemetry bug
- Telemetry bug fix: We've deployed a patch to address the thread-locking bug in our telemetry library. This fix prevents the thread contention issues that previously slowed down API Gateway's event loop when it was experiencing a high load.
- Telemetry library hardening: After deploying the fix, we updated our telemetry library microbenchmark harness test suite to include multithreaded tests for the code path that caused thread contention.
Improvements to detecting page deployment failures
- Add additional release guardrails: We'll include page load completion events as a page asset canary release indicator. At the moment, our automated canary release includes the JavaScript error rate as the primary indicator. We'll include page load events as a secondary indicator.
- Increase canary duration: We're experimenting with adding another rollout stage to our canary to provide more time to detect issues as staged rollouts progress.
- Asset fetching timeouts: We're adding timeouts to prevent user requests from waiting excessively long to retrieve assets, reducing the impact of future consolidated requests.
Collaboration with Cloudflare
- Working with Cloudflare: We've been working closely with Cloudflare to gain an in-depth understanding of the complex system interactions involved in the incident.
Next steps
Our mission at Canva is to empower the whole world to design, which is impossible to achieve without a system our users and customers can rely on.
After performing an extensive analysis and writing an internal incident report, we have short-term and long-term action items that we'll keep working on to improve Canva's reliability and make sure we stay true to our mission.
Canva has a long history of writing incident reports to make sure we learn from every outage. We've been following our internal incident process, requiring an incident report for every high- or medium-severity incident, since we formalized the process in 2017. This is our first publicly shared incident report. We're doing this as part of our commitment to transparency, accountability, and continuous improvement, and to share our learnings with the rest of the industry.
This post was prepared with contributions from Ben Mitchell(opens in a new tab or window), Sergey Tselovalnikov(opens in a new tab or window), and Steve Strugnell(opens in a new tab or window).